Week 6 Update
- Bradley Schulz
- Feb 18, 2023
- 6 min read

Dealing issues that come from testing the system in real life...
Goals from This Past Week
Team goals: Integrate the code Tyler and I have created to create a unified software system.
Personal goals: Increase the accuracy given new data from the integrated system.
Integration Issues
Tyler had saved a few images from his card localization work that I was able to plug into my classification algorithms. After feeding these images into my classification code, I noticed a few common issues:
Random dots affected the bounding rectangles for each shape
Multiple shapes may be close enough to be read as a single shape
Some images had very washed out colors which led to improper color classification
Below are two examples of noise interfering with the shape bounding rectangles (issue 1).

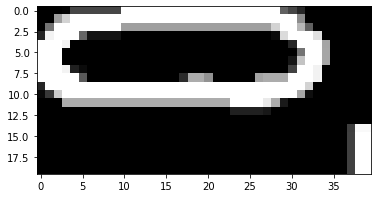
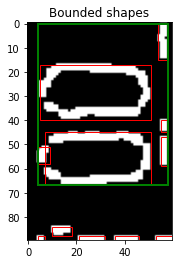
In one case, these extra dots even caused two adjacent shapes to be interpreted as one single shape (issue 2). Below (from left to right) are the raw image, grayscale version (with the raw bounding rectangles in red and final bounding rectangle in green), and the resized image of the single "shape".




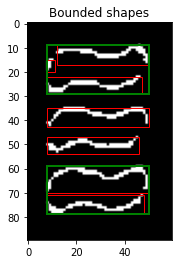
However, I didn't want to completely stop combining nearby rectangles, as this technique is very useful when the border of a shape is not continuous. See the example below:

These issues primarily impact the classification of the type of shape, since that algorithm assumes that each bounding rectangle exactly encompasses a single shape and then calculates the absolute area of the shape within the bounding rectangle. Since the different shapes have different areas, it tries to use that to distinguish between shapes. To fix this, I could try to either make the bounding rectangles more precise or find an alternate method of classifying the type of shape. I ended up trying both approaches.
Fixing the Bounding Rectangles
First, I removed the dilation step in pre-processing to see if that gets rid of the extra dots. Then, I played around with the erosion kernel to see if I could preserve more of the original shape. However, that did not solve all the problems. There were still images left like the one below with a lot of noise on the side:

I noticed that a lot of noise comes from improper bounding of the edges of the card. To fix that, I added a hard cutoff where the algorithm ignores points at the far left and far right of the image. I also played around with the blur function used in the pre-processing steps to see if that smooths out more of the noise. After both these changes, I was left with the following (correct) bounding for the previous shape:

However, a side effect of these updates is that this caused other shapes with poorly defined borders to split into two shapes. This is because the erosion step in pre-processing removes shape borders that are too faint, and the resulting gap between them is too large for the algorithm to know to combine it into one shape.



It seems that the pre-processing needs to strike a balance between blurring out enough irrelevant noise while not removing too much of the shape borders.
I stopped making updates at this point because, unfortunately, Tyler and I decided we may need to pivot a different solution for finding bounding rectangles. Since Tyler has had more trouble than anticipated with image pre-processing using the OpenMV functions (instead of the OpenCV ones I have been using on Google Colab), we may switch to checking the cards against pre-defined bounding rectangles using the binary masks below.



I set up code apply these binary masks to a 60x90 image of a card so we could zero-out irrelevant sections, and then I handed this code off to Tyler so he could experiment with it. I'll let him cover more details about that in his own blog post.
Color Classification
I also changed the way colored pixels are identified. Previously, I examined pixels within the shapes' bounding rectangle to determine the standard for a white pixel in the image. However, I changed the algorithm to examine the pixels in a 5 pixel border around the shape to determine the standard for white pixels. This increases the accuracy of the threshold for non-colored pixels because it reduces the potential that colored pixel could be used as part of the baseline measurement of a white pixel.
Shape Classification Using a CNN
Since I got identifying the correct bounding rectangles working well enough on Google Colab, I was able to do some more work on an alternate algorithm to identify the type of shape. Using the 12 training images Tyler gave me, I attained the following accuracy with the old shape classification algorithm:

I decided to try using a CNN to classify the shapes. I used a model architecture with just under 800 parameters (the entire model is only 4284 bytes), which is incredibly small for a CNN. I was able to achieve this few parameters because the classification task is fairly simply — it's just taking a 20x40 grayscale image and identifying one of three shapes.

I trained this model on images from a training dataset on GitHub that I used earlier in this project. Using this, I trained the model to get 99% accuracy on testing data.

Then I had to save this model so it could work with tensorflow lite on the H7. This ended up being a much more involved process than I intended, since I had to adjust the model architecture and convert it to tensorflow lite format. After a few hours of parsing through various online resources, I finally got the model to save as a single file that we could ultimately upload to the H7.
I tested the tensorflow lite model on the images from Tyler on Google Colab, and now the accuracy is much higher. I assume the remaining issues lie in the training dataset being much more perfect than the images we actually get on the H7. To improve the accuracy, I need more training data from Tyler. I could also play around with augmenting the training dataset through adding noise.

However, after all this work, I was unable to get this CNN running on the H7. When I tried to load the model, the H7 simply crashed and gave no error message. I talked to other people who had gotten a CNN working on OpenMV, and we could not debug the issue. I decided to put integrating the CNN on hold until we decide for certain if we need one in our system. Taking even more hours to debug this issue does not seem worth it given that we don't even know if we will need this CNN.
This whole CNN task was more of an exploration of an alternate shape classifier in case we want to use it. I think it is likely we will ultimately want a CNN since it is more robust at classification and this simple CNN doesn't take too much memory. But at this stage, it is not worth trying too hard to debug this unknown issue.
Code Refactoring
A lot of the work this week gave me a headache, so I switched to something easier and decided to work on making our code prettier. With this, it will ideally be easy to combine the end results from all our sub-tasks (localization, classification, set identification, etc.) once they are all complete.
To keep everything organized, I moved the code I have written into the following 3 library files:
classifier.py --> Code to take a 60x90 image of a card and determine what card it is
set_detector.py --> Given a list of 12 cards, determine all sets
matrix.py --> control the LED matrix that displays sets
I am also hoping to consolidate Tyler's code into one or two files that do preprocessing and card localization. With that, the main code should be very clean and just look like this:
# Take picture
img = sensor.snapshot()
# Preprocess
img_gray, img_rgb = preprocess(img)
# Extract cards
extracted_cards = extract_cards(img_gray, img_rgb)
# Classify each card
cards = [classify_card(c) for c in extracted_cards]
# Identify Sets
sets = find_sets(cards)In consolidating all these files, I also did some work transitioning my code to work in the OpenMV IDE. This meant removing some of the tricks to make my code prettier using Python libraries (such as using numpy, Enums, and function decorators) so that the code could compile given the fewer libraries available in MicroPython.
Next Steps
I am in a bit of a tricky situation in that I am not exactly sure what approaches will end up working best on the H7. A lot of the code that worked really well on Google Colab has been hard to make successful on the H7, and I need to work more closely with Tyler in the coming week(s) to work on overcoming these issues. I have a lot of ideas set up to test on the H7, but we need more testing data to figure out what will work best. To help with this, I will need to find an SD card I can use to increase the memory available and load more testing images to the H7.
Goals for Next Week
Team goal: Determine which algorithms/approaches we want to use in the end preprocessing and classification system.
Personal goals: Continue porting my classification code to OpenMV. Given additional training data from Tyler, I will test my classification algorithms for robustness.



Comments